|
|
|||||||||||||||||||
| <Добавить в Избранное> <Сделать стартовой> <Реклама на сайте> <Контакты> | |||||||||||||||||||
|
|||||||||||||||||||
| |||||||||||||||||||
|
| |||||||||||||||||||
Раздел: Компьютерная документация -> Базы данных -> SQL | |||||||||||||||||||
Рефакторинг SQL-запросовСодержание
Практически любой разработчик приложений баз данных сталкивается с необходимостью переделки ранее написанных SQL-запросов. При этом обычно преследуются две цели: во-первых - оптимизация времени выполнения запроса, во-вторых - улучшение дизайна запроса. Этот процесс подпадает под определение одной из основных практик экстремального программирования - рефакторинга (улучшения качества кода без изменения его функциональности). Основная масса литературы по рефакторингу посвящена переделке кодов программ, написанных на алгоритмических языках, и касается, как правило, объектно-ориентированных аспектов программирования. Целью данной статьи является попытка описания практики рефакторинга для SELECT-запросов языка SQL. Признаки необходимости модификации запросовПрежде чем заниматься переделкой кода, для начала надо четко определить, чем он плох, к чему надо стремиться, какими характеристиками должен обладать «совершенный запрос». Ниже предлагается ряд признаков «плохого» кода, при этом подразумевается, что по функциональности запрос уже нас устраивает и выдает в точнсти те данные, которые требуются. 1-ый признакКод может быть «плохо оформлен», в этом случае его сложно понимать, соответственно - сложно переделывать. Для разработчика это должно означать несоответствие оформления запроса некоторым правилам, стандарту кодирования. Если не рассматривать правила именований объектов баз данных (считается, что схему данных изменить нельзя), то стандарт кодирования должен описывать, как должен быть отформатирован запрос (отступы, пробелы, длина строк…) и как должны именоваться объявляемые в его рамках переменные и алиасы (псевдонимы). Сюда же можно отнести требование использования только стандартных ключевых слов языка SQL и только в несокращенной форме. Наглядно пользу форматирования кода можно продемонстрировать на следующем примере - листинг 1.
SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit,
Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount,
Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products
ON Suppliers.SupplierID = Products.SupplierID INNER JOIN
OrderDetails ON Products.ProductID = OrderDetails.ProductID
INNER JOIN Orders ON
OrderDetails.OrderID = Orders.OrderID WHERE
(OrderDetails.Discount = 0) AND
(Orders.OrderDate > '06/11/1996')
Листинг 1. Пример неформатированного запроса. Тот же запрос после обработки может выглядеть так: SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996') Листинг 2. Запрос после проведения форматирования. 2-ой признакТочно так же, как и для алгоритмических языков, проблемой, с точки зрения дизайна и сопровождения, является наличие дублирующего кода. Устранение этих двух недостатков (1-го и 2-го признака), скорее всего не изменит скорость выполнения запроса, но поможет лучшему пониманию его структуры и упростит внесение дальнейших изменений. Следующие признаки «плохих» запросов будут связаны уже с их структурой. Поскольку все они определяются через наличие некоторых конструкций языка SQL, то воспринимать их нужно с оговоркой, что использование данных конструкций в запросе не является безальтернативным и от них можно избавиться. 3-ий признакНевозможность визуального представления запроса. В качестве инструмента проверки на соответствие данному признаку можно предложить Query Designer из MS SQL Server. Наверное очевидно, что визуальное представление запроса помогает пониманию его структуры. Состав критичных конструкций языка SQL для этого признака можно взять из документации по SQL Server (Books Online, статья «Query Designer Considerations for SQL Server Databases»). В частности, таковой является конструкция UNION. Рис.1. Визуальное представление запроса 4-ый признакНаличие в запросе медленно работающих конструкций. В качестве примера можно привести использование связанных подзапросов. Избавление от подзапросов помимо увеличения скорости выполнения запроса, в большинстве случаев улучшит его читаемость. Предложения UNION также относятся к медленно работающим, т.к. в них требуется отбрасывать избыточные дубликаты [3]. 5-ый признакНевозможность построения на основе запроса индексированного представления. Если забежать вперед и предположить, что, несмотря на все ухищрения, запрос работает недостаточно быстро, то следующим способом его ускорить можно предложить получение требуемых данных на основе индексированного представления. Перечень ограничений можно опять же получить из документации SQL Server (Books Online, статья «Creating an Indexed View»). В «черный список» снова попали подзапросы и UNION, а также:
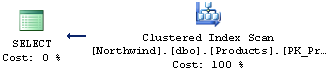
Соответствие всем этим требованиям - конечно же, очень сильное ограничение. Естественно, что далеко не все запросы можно перестроить в соответствие с ними. Важно, чтобы программист понимал критичность использования некоторых конструкций с точки зрения производительности и дизайна кода. Во многих ситуациях реально из запроса выделить часть, удовлетворяющую ограничениям индексированного представления и построить индексированный view только для этой части. Методы модификации запросовДля минимизации риска Мартин Фаулер[2] рекомендует проводить рефакторинг «маленькими шажочками», осуществляя проверку результата после каждого из них. Часть его книги составляет каталог методов рефакторинга - попытка классифицировать и описать наиболее часто встречающиеся модификации кода (предназначенные, прежде всего, для объектно-ориентированного программирования). Подобный каталог можно составить и для SQL. Ниже, в качестве примера, приведены четыре метода рефакторинга для наиболее простых ситуаций. 1. Выделение пользовательской функцииМотивом для проведения такого рефакторинга является частое использование некоторых стандартных вычислений, встречающееся в рамках одного запроса или группы запросов. Пример: расчет первого числа месяца для некоторой даты на языке SQL: DATEADD(dd, 1-DAY(@date), @date) Понятно, что запись не является особо сложной или громоздкой, но, тем не менее, ее многократное использование не способствует улучшению читаемости кода. Если поместить этот расчет в функцию, ее вызов будет выглядеть так: FirstDayOfMonth(@date) Такая запись уже не требует написания комментария (лучшая документация для исходного кода - это он сам). 2. Выделение представленияЭто преобразование может быть оправдано как для повторяющегося участка кода, встречающегося в группе запросов, так и для отдельного запроса. Информативное имя представления также повысит читаемость кода. Особенностью данной модификации является то, что выделяемый участок кода не будет неразрывным в исходном запросе. В листинге 3 цветовым выделением обозначены фрагменты кода, которые необходимо перенести в представление, содержащее информацию таблиц Order и OrderDetails. SELECT Suppliers.CompanyName, Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount, Orders.OrderDate, Orders.ShipName FROM Suppliers INNER JOIN Products ON Suppliers.SupplierID = Products.SupplierID INNER JOIN OrderDetails ON Products.ProductID = OrderDetails.ProductID INNER JOIN Orders ON OrderDetails.OrderID = Orders.OrderID WHERE (OrderDetails.Discount = 0) AND (Orders.OrderDate > '06/11/1996') Листинг 3. Фрагменты кода, формирующие представление. Эта особенность требует проведения значительного количества мелких действий при осуществлении подобного преобразования вручную. 3. Избавление от подзапросовЧасто причиной появления в коде подзапроса связано с переносом практики работы с циклами в алгоритмических языках и неумением думать в терминах теории множеств. Простейший случай может выглядеть следующим образом: SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, (SELECT CompanyName FROM Suppliers WHERE Suppliers.SupplierID = Products.SupplierID) AS CompanyName FROM Products Листинг 4. Простейший пример использования связанного подзапроса Рис. 2. План выполнения запроса из листинга 4. Того же результата можно добиться и без использования подзапроса: SELECT Products.ProductName, Products.QuantityPerUnit, Products.UnitPrice, Suppliers.CompanyName FROM Products LEFT OUTER JOIN Suppliers ON Suppliers.SupplierID = Products.SupplierID Листинг 5. Вариант модификации запроса из листинга 4. Рис. 3. План выполнения модифицированного запроса из листинга 5 При рассмотрении планов выполнения запросов, видно, что планы выполнения обоих запросов практически одинаковые. План для исходного запроса на одно действие короче, но в процентном соотношении различие составляет менее 1%. Здесь нужно принимать во внимание, что оптимизаторы современных СУБД достаточно эффективно «разгоняют» простые запросы со связанными подзапросами. Для более сложных запросов разница может быть существеннее. Большинство ситуаций, встречающихся в реальных запросах, сложнее, тем не менее, в модифицированном запросе должен будет появиться JOIN с таблицей (таблицами) из подзапросов. При использовании агрегатных функций в подзапросе - они перейдут в основной запрос, к которому будет добавлено предложение GROUP BY (см. листинги 6,7). SELECT OrderDate, ShipName, (SELECT SUM(UnitPrice*Quantity) FROM OrderDetails WHERE OrderDetails.OrderID = Orders.OrderID) AS OrderSum FROM Orders Листинг 6. Пример SELECT-команды с агрегатной функцией в подзапросе SELECT Orders.OrderDate, Orders.ShipName, SUM(OrderDetails.UnitPrice*OrderDetails.Quantity) AS OrderSum FROM Orders LEFT OUTER JOIN OrderDetails ON OrderDetails.OrderID = Orders.OrderID GROUP BY Orders.OrderID, Orders.OrderDate, Orders.ShipName Листинг 7. Вариант модификации запроса из листинга 6. 4. Избавление от UNIONНаиболее простым примером использования UNION, от которого можно избавиться, является цепочка предложений UNION, основанных на одной и той же базовой таблице. Примеры исходного запроса и преобразованного приведены в листингах 8,9. SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%' UNION SELECT ProductID, ProductName, UnitPrice FROM Products WHERE UnitPrice <= 40 Листинг 8. Запрос с UNION на основе одной базовой таблице SELECT ProductID, ProductName, UnitPrice FROM Products WHERE ProductName LIKE 'A%' OR UnitPrice <= 40 Листинг 9. Модифицированный запрос (замена UNION на OR) Очевидно, что модифицированный запрос имеет более простой дизайн. Для наглядной иллюстрации критичности использования UNION, ниже приведены планы выполнения этих запросов. Рис. 4. План выполнения запроса с UNION (из листинга 8)
Рис. 5. План выполнения запроса после замены UNION на OR В некоторых ситуациях в использовании UNION нет необходимости и достаточно более производительного предложения UNION ALL (при его выполнении не происходит объединения повторяющихся строк). Программные средства рефакторинга SQLДействия программиста, выполняемые при проведении рефакторинга, можно поделить на 3 группы: форматирование кода, непосредственное применение методов рефакторинга - преобразований кода и проверку того, что конечный запрос не отличается от исходного по набору возвращаемых данных. Частично эти действия могут быть автоматизированы, точно так же, как они автоматизируются для ряда объектно-ориентированных языков программирования. Ниже приведен краткий обзор средств, которые могут быть использованы для рефакторинга SQL-запросов. Обзор не претендует на полноту и ориентирован, в основном, на программные инструменты, входящие в состав средств разработки компании Microsoft или дополняющие их. 1. Форматирование кода и визуальное представлениеСуществует довольно большой набор средств форматирования SQL-кода. В их числе: Query Designer, входящий в состав SQL Server Management Studio - для форматирования достаточно скопировать запрос и активизировать панель визуального представления. Из средств сторонних разработчиков можно привести в качестве примера SQL Refactor компании Red Gate Software и QueryCommander - бесплатный инструмент с открытым кодом. Основные различия указанных средств - в разных стандартах форматирования, к которым они приводят исходные запросы и в возможности изменить это параметрами настроек. 2. Программы для рефакторинга запросовАвтору статьи не удалось найти средства, автоматизирующие непосредственно проведение рефакторинга SQL-кода. Единственный программный продукт, который претендует на эту роль (по крайней мере - по названию) - SQL Refactor, предлагает только возможности форматирования кода, выделение части SQL-кода в качестве хранимой процедуры и разбиение предложения CREATE TABLE на две части (с разделением уже существующих колонок между двумя таблицами). Никаких сервисов по модификации структуры запросов не предлагается. 3. Unit-тестирование для SQL-запросовВ экстремальном программировании практика проведения рефакторинга тесно связана с практикой написания тестов модулей, или unit-тестов. Основная аргументация связи этих практик - невозможность смело переделывать работающий код, если нет механизмов быстрой проверки того, что внесенные изменения его не испортили. В принципе, вполне возможно написание unit-тестов средствами, приспособленными для тестирования программ алгоритмических языков (jUnit, csUnit, встроенными механизмами написания unit-тестов в MS Visual Studio 2005). В случаях, если запросы пишутся для серверных компонентов, обеспечивающих доступ к базам данных, эти тесты могут вполне органично вписываться в общую систему тестирования этих компонентов. При этом необходимо учитывать особенность тестирования запросов: нужны механизмы сравнения наборов данных, а не отдельных значений. Удалось найти всего три средства построения unit-тестов, связанных с тестированием SQL-запросов: SQLUnit, DbUnit и TSQLUnit. Все три средства являются узкоспециализированными: DbUnit и SQLUnit исходно ориентированы на Java-разработчиков, TSQLUnit - требует написания unit-тестов на языке Python. Из них только в DbUnit есть функция сравнения наборов данных, в двух оставшихся - такая возможность отсутствует. ЗаключениеПодход к проведению модификации существующего кода вполне оправдывает себя в применении к SQL-запросам. К сожалению, на сегодняшний день выбор средств автоматизации рефакторинга SQL весьма скуден, а имеющиеся средства недостаточно функциональны. Это скорее всего связано с тем фактом, что XP зародилось в среде разработчиков, программирующих преимущественно на объектно-ориентированных языках и специфичностью характера проведения рефакторинга для SQL-кода. Литература:
Автор: Алексей Петров
|
|||||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| Copyright © CompDoc.Ru | ||||||||||||||||
| При цитировании и перепечатке ссылка на www.compdoc.ru обязательна. Карта сайта. |