|
|
||||||
| <Добавить в Избранное> <Сделать стартовой> <Реклама на сайте> <Контакты> | ||||||
|
||||||
| ||||||
|
| ||||||
Программирование -> C/C++ -> Сущность технологии COM |
Эволюция объектовСокращенную версию этого очерка предполагается опубликовать в январском, 1998 года, выпуске Microsoft Systems Journal. Здесь этот очерк включен в приложение, поскольку в нем СОМ рассматривается в исторической перспективе. Развитие объектно-ориентированного программирования перешло в стадию коммерческого применения в конце 1980-х годов. Центральной темой объектного ориентирования в середине 1980-х было использование классов, которые позволили разработчикам моделировать состояние и поведение как единый абстрактный модуль. Такая упаковка состояния и поведения помогает провести в жизнь модульный принцип через применение инкапсуляции. В классическом объектном ориентировании объекты принадлежали классам, а клиенты манипулировали объектами посредством основанных на классах ссылок. Такая модель программирования принята в большинстве сред и библиотек C++ и Smalltalk тех времен. В то время программисты, придерживающиеся строгого стиля, могли извлечь максимальную пользу из классового подхода, составляя программы на языках, широко применяющих процедуры. Однако действительно широкое распространение объектно-ориентированного программирования наступило только тогда, когда объектное ориентирование стало явно поддерживаться разработчиками языков программирования и сервисных программ. К числу программных сред, сыгравших важнейшую роль в обеспечении успеха объектного ориентирования, относятся оболочка МасАрр фирмы Apple на базе Object Pascal, первые среды SmallTalk фирм ParePlace и Digitalk, а также Turbo C++ фирмы Borland. Одним из ключевых преимуществ использования среды разработки, явно поддерживающей объектное ориентирование, была возможность применения полиморфизма для интерпретации групп сходных объектов как совместимых друг с другом по типу. С целью поддержки полиморфизма в объектном ориентировании были введены понятия наследования и динамического связывания, что позволило явно группировать сходные объекты в коллекции (collections) связанных абстракций. Рассмотрим следующую простейшую иерархию классов C++: class Dog {
public:
virtual void Bark(void);
};
class Pug : public Dog {
public:
virtual void Bark(void);
};
class Collie : public Dog {
public:
virtual void Bark(void);
};
Поскольку классы Collie и Pug оба совместимы по типу с классом Dog, то клиенты могут написать групповой (generic) код следующим образом: void BarkLikeADog(Dog& rdog)
{
rdog.Bark();
}
Поскольку метод Bark является виртуальным и динамически связанным, механизмы диспетчеризации методов C++ обеспечивают выполнение нужного кода. Это означает, что функция BarkLikeADog не полагается на точный тип объекта, на который она ссылается; ей достаточно, чтобы это был тип, совместимый с Dog. Данный пример может быть легко переделан для любого числа языков, поддерживающих объектно-ориентированное программирование. Приведенная иерархия классов является типичным примером тех приемов, которые применялись во время первой волны развития объектного ориентирования. Одной из основных характеристик этой первой волны было наследование реализаций. Наследование реализаций является мощным приемом программирования, если применять его строго по правилам. Однако при его неправильном применении результирующая иерархия типов может стать образцом чрезмерной связи между базовым и производным классами. Типичным недостатком такой связи является то, что зачастую неясно, должна реализация метода базовым классом вызываться из версии порожденного класса или нет. Для примера рассмотрим реализацию Bark класса Pug: void Pug::Bark(void)
{
this->BreathIn();
this->ConstrictVocalChords();
this->BreathOut();
}
Что произойдет, если реализация Bark основным классом Dog не вызвана, как в случае приведенного выше фрагмента кода? Возможно, метод базового класса записывает для дальнейшего использования, сколько раз лает (barks) конкретная собака (dog)? Если это так, то класс Pug вторгся в соответствующую часть реализации базового класса Dog. Для правильного применения наследования реализаций необходимо нетривиальное количество внутреннего знания для обеспечения сохранности базового класса. Это количество детального знания превышает уровень, требующийся для того, чтобы просто быть клиентом базового класса. По этой причине наследование реализации часто рассматривается как повторное использование белого ящика. Один из подходов к объектному ориентированию, сокращающий чрезмерную связь систем типов, но сохраняющий преимущества полиморфизма, заключается в том, чтобы наследовать только сигнатуры типов, но не код реализации. Это является фундаментальным принципом разработок на базе интерфейса, что можно рассматривать как вторую волну объектного ориентирования. Программирование на базе интерфейса является усовершенствованием классического объектного ориентирования, которое считает, что наследование является прежде всего механизмом для выражения отношений между типами, а не между иерархиями реализаций. В основе интерфейсно-ориентированных разработок лежит принцип отделения интерфейса от реализации. В этом направлении интерфейсы и реализации являются двумя различными понятиями. Интерфейсы моделируют абстрактные требования, которые могут предъявляться к объекту. Реализации моделируют конкретные обрабатываемые типы, которые могут поддерживать один или более интерфейсов. Многие из этих преимуществ интерфейсно-ориентированного развития могли быть достигнуты и традиционными средствами первой волны в рамках строгого стиля программирования. Однако широкое принятие этого направления произошло только тогда, когда была получена явная поддержка со стороны разработчиков языков и инструментальных средств программного обеспечения. В число программных сред, сыгравших главную роль в обеспечении успеха интерфейсно-ориентированного развития, входят модель компонентных объектов (Component Object Model - СОМ) фирмы Microsoft, программная среда Orbix Object Request Broker фирмы Iona и Digitalk, а также явная поддержка интерфейсно-ориентированной разработки в рамках языка Java1. Одним из основных преимуществ использования программной среды, поддерживающей интерфейсно- ориентированное развитие, являлась возможность смоделировать, "что" и "как" делает объект, как две различные концепции. Рассмотрим следующую простейшую иерархию типов для Java: interface IDog {
public void Bark();
};
class Pug implements IDog {
public void Bark( ){...}
};
class Collie Implements IDog {
public void Bark( ){...}
};
Поскольку оба класса - Collie и Pug - совместимы с интерфейсом IDog, то клиенты могут написать групповой код следующим образом: void BarkLikeADog(IDog dog)
{
dog.Bark();
}
С точки зрения клиента, эта иерархия типов практически идентична предыдущему примеру на C++. В то же время, поскольку метод Bark интерфейса IDog не может иметь реализации, между определением интерфейса IDog и классами Pug или Collie не существует связи. Хотя из этого следует, что как Pug, так и Collie должны полностью определить свое собственное представление о том, что означает "лаять" (bark), конструкторы Pug и Collie не обязаны интересоваться, какие побочные эффекты окажут их производные классы на основной базовый тип IDog. Поразительное подобие между первой и второй волной заключается в том, что каждая из них может быть охарактеризована с помощью простого понятия (класс и интерфейс, соответственно). В обоих случаях катализатором успеха послужило не само понятие. Для разжигания интереса со стороны индустрии программирования в целом потребовалась еще одна или несколько ключевых программных сред. Интересной стороной систем второй волны является то, что реализация рассматривается как черный ящик. Это означает, что все детали реализации считаются непрозрачными (opaque) для клиентов объекта. Часто, когда разработчики начинают использовать такие основанные на интерфейсах технологии, как СОМ, то уровень свободы, которую дает эта непрозрачность, игнорируется, что побуждает неопытных разработчиков весьма упрощенно рассматривать отношения между интерфейсом, реализацией и объектом. Рассмотрим электронную таблицу Excel, которая выставляет свои функциональные возможности, используя СОМ. Реализация класса электронной таблицы Excel выставляет около 25 различных интерфейсов СОМ, что позволяет ей применять множество основанных на СОМ технологий (Linking, Embedding, Inplace Activation, Automation, Active Document Objects, Hyperlinking и т. д.). Поскольку каждому интерфейсу требуется по четырехбайтному указателю виртуальной функции (vptr) на объект, объекты электронной таблицы заполняют около 100 байт служебными данными, в добавление к любому конкретному состоянию электронной таблицы, которое может потребоваться для хранения пользовательских данных. Поскольку данный объект электронной таблицы может состоять из весьма большого количества ячеек, эти 100 байт служебных данных погашаются сотнями килобайт, которые может потребовать большая таблица для управления содержимым каждой используемой ячейки.
Фактическая реализация электронной таблицы Excel осложняется тем, что к каждой отдельной ячейке электронной таблицы можно обращаться также через интерфейсы СОМ. С точки зрения СОМ каждый из интерфейсов ячейки представляет собой определенную идентификационную единицу СОМ и не может быть обнаружен с помощью опросов объекта электронной таблицы функцией QueryInterface. Вместо этого интерфейсы ячеек обнаруживаются путем использования одного из альтернативных интерфейсов (например, IOleItemContainer), которые объект электронной таблицы выставляет для своих клиентов. Тот факт, что теперь каждая ячейка раскрывается для клиентов через интерфейсы СОМ, означает, что разработчик Excel должен позаботиться о недопущении чрезмерного количества служебных данных, относящихся к СОМ. Рассмотрим объект электронной таблицы, состоящей из 1000 ячеек. Предположим для простоты вычислений, что каждой ячейке требуется в среднем по 16 байт памяти для хранения исходного состояния ячейки Excel. Это означает, что таблица из 1000 элементов потребляет примерно 16 000 байт памяти, не связанной с СОМ. Для этой таблицы 100 байт служебных записей указателя виртуальной функции, помещенных интерфейсами табличного уровня, оказывают очень малое влияние на потребление памяти. Однако поскольку каждая отдельная ячейка может самостоятельно выставлять примерно восемь отдельных интерфейсов СОМ, то для каждой ячейки 32 байта могут быть заняты для служебных записей, касающихся управления указателями виртуальных функций ячейки. При использовании простых технологий реализации, которые включены в большинство сред разработки СОМ, 1000-ячеечной электронной таблице понадобится примерно 32 100 байт памяти для указателей виртуальных функций, что примерно вдвое превышает объем памяти, занимаемой исходными данными Excel. Ясно, что такие служебные записи чрезмерны.
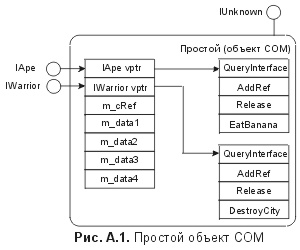
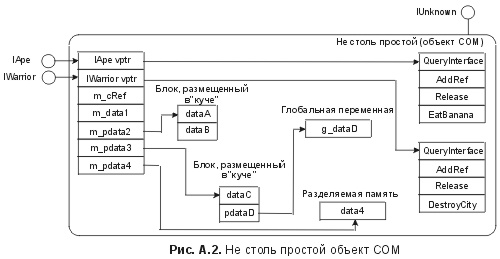
Для того чтобы понять, как команда разработчиков Excel решила данную проблему расхода памяти на указатели vptr, полезно вновь проверить отношения между состоянием и поведением, как оно обычно реализовано в СОМ. На рис. A.1 показан простейший объект СОМ в памяти. Отметим, что блок памяти, занимаемый объектом, состоит из указателей vptr и элементов данных. Можно рассматривать этот рисунок, считая, что элементы данных представляют состояние объекта, а указатели виртуальных функций - его поведение. В большинстве реализаций объектов эти два аспекта объекта записаны в непрерывном блоке памяти. Однако СОМ не настаивает на этом. СОМ просто имеет дело с указателями vptr, а управление состоянием предоставляет разработчику. СОМ вполне счастлив, если разработчик решит разместить состояние объекта и vptr в различных блоках памяти, как показано на рис. А.2. В конце концов, то, как происходит управление состоянием объекта, является всего лишь одной из деталей реализации, скрытой от клиента за стеной интерфейсов объекта. Так как СОМ не требует, чтобы состояние объекта было размещено рядом с его указателями vptr, команда разработчиков Excel смогла значительно уменьшить потребление памяти. Рассмотрим отдельную ячейку электронной таблицы. Хотя для записи содержимого ячейки необходимо выделить 16 байт памяти, но 32 байта памяти, необходимых для vptr ячейки, не обязательно размещать в едином блоке памяти вместе с данными ячейки. Кроме того, если к ячейке не осуществляется доступ через ее СОМ-интерфейсы, то эти 32 байта памяти для vptr вообще не нужны. Это означает, что Excel может просто динамически размещать блоки памяти для vptr, по принципу "ячейка к ячейке" (cell-by-cell). Поскольку к большей части ячеек обращения через интерфейсы СОМ не будет никогда, это означает, что фактически в большинстве случаев не будет и затрат на vptr. Этот принцип создания "невесомых" объектов (flyweight objects), предназначенных для обеспечения поведения по необходимости, является вариантом "отделяемой" (tearoff) технологии, которая была впервые предложена в великолепной книге Криспина Госвелла "Сборник рецептов программиста СОМ" (Crispin Goswell. СОМ Programmer's Cookbook) ( http://www.microsoft.com/oledev). Обе эти технологии используют отложенное вычисление (lazy evaluation) для задержки выделения памяти указателям vptr. Невесомые и отделяемые элементы являются технологиями разработки СОМ, однако сама СОМ не дает им полномочий и не поддерживает явно. Эти технологии возникли из необходимости эффективно управлять состоянием. При использовании СОМ для разработки распределенных приложений возникают дополнительные проблемы управления состоянием, в том числе исправление распределенных ошибок, безопасность, управление параллелизмом, уравновешивание загрузки и непротиворечивость данных. К сожалению, СОМ ничего не знает о том, как объект управляет своим состоянием, так что она мало может помочь в разрешении этих проблем. Хотя разработчики могут изобретать свои собственные схемы управления состоянием, имеются явные преимущества в построении общей инфраструктуры для развития объектов со знанием своего состояния. Одной из таких инфраструктур является Microsoft Transaction Server (Сервер транзакций фирмы Microsoft - MTS). Модель программирования СОМ расширила традиционную модель объектно-ориентированного программирования, заставив разработчиков вникать во взаимоотношения между интерфейсом и реализацией. Модель программирования с MTS также расширяет модель СОМ, побуждая разработчиков вникать также и во взаимоотношения между состоянием и поведением. Фундаментальный принцип MTS заключается в том, что объект может быть логически смоделирован как состояние и поведение, но его физическая реализация должна явно различать эти понятия. Явно разрешив MTS управлять состоянием объекта, разработчик приложения может усилить поддержку инфраструктурой управления параллелизмом и блокировкой, локализацией ошибок, непротиворечивостью данных, а также контролем доступа на уровне мелких структурных единиц (fine-grain). Это означает, что большую часть состояния объекта можно не записывать в непрерывный блок с их указателями vptr (представляющими поведение объекта). Вместо этого в MTS предусмотрены средства для записи состояния объекта либо в длительное, либо во временное хранилище. Это хранилище находится под контролем среды MTS на этапе выполнения, и к нему обеспечен безопасный доступ для методов объекта, причем не нужно заботиться об управлении блокировкой и совместимости данных. Состояние объекта, которое должно оставаться постоянным в случае сбоя машины или нештатного прекращения работы программы, записывается в долговременное хранилище, и MTS гарантирует лишь ничтожные изменения во всей сети. Переходное состояние может быть записано в память, управляемую MTS, причем MTS гарантирует то, что обращения к памяти будут последовательными - во избежание порчи информации. Как в разработках на базе классов и на базе интерфейсов, модель программирования MTS, конструирующая состояние, требует дополнительного внимания и дисциплины со стороны разработчика. К счастью, как и с разработкой моделей на базе классов и на базе интерфейсов, модель MTS, конструирующая состояние, может быть принята постепенно. Конечно, пошаговое принятие означает, что преимущества MTS будут реализованы также постепенно. Это позволяет разработчикам принимать MTS со скоростью, соответствующей местной культуре программирования. После объединения команд разработчиков MTS и СОМ в рамках фирмы Microsoft стало ясно, что MTS являет собой следующий шаг в эволюции СОМ. Я горячо призываю всех разработчиков СОМ включиться в эту третью волну развития объектно-ориентированного программирования. 1 В действительности Java также поддерживает и традиционное наследование реализаций, в отличие от СОМ, и практически всех продуктов в стиле CORBA (например, Orbix фирмы Iona, DSOM фирмы IBM, Object Broker фирмы BEA). |
| |||||||||||
| |||||||||||
| |||||||||||