|
|
||||||||||||||||
| <Добавить в Избранное> <Сделать стартовой> <Реклама на сайте> <Контакты> | ||||||||||||||||
|
||||||||||||||||
| ||||||||||||||||
|
| ||||||||||||||||
Программирование -> C/C++ -> Программирование на языке Си | ||||||||||||||||
2.2. Сортировка И Слияние СписковПри работе со списками очень часто возникает необходимость перестановки элементов списка в определенном порядке. Такая задача называется сортировкой списка и для ее решения существуют различные методы. Рассмотрим некоторые из них. 2.2.1. Пузырьковая сортировкаЗадача сортировки заключается в следующем: задан список целых чисел (простейший случай) В=< K1, K2,..., Kn >. Требуется переставить элементы списка В так, чтобы получить упорядоченный список B'=< K'1, K'2,...,K'n >, в котором для любого 1<=i<=n элемент K'(i) <= K'(i+1). При обменной сортировке упорядоченный список В' получается из В систематическим обменом пары рядом стоящих элементов, не отвечающих требуемому порядку, пока такие пары существуют. Наиболее простой метод систематического обмена соседних элементов с неправильным порядком при просмотре всего списка слева на право определяет пузырьковую сортировку: максимальные элементы как бы всплывают в конце списка. Пример:
B=<20,-5,10,8,7>, исходный список;
B1=<-5,10,8,7,20>, первый просмотр;
B2=<-5,8,7,10,20>, второй просмотр;
B3=<-5,7,8,10,20>, третий просмотр.
В последующих примерах будем считать, что сортируется одномерный массив (либо его часть от индекса n до индекса m) в порядке возрастания элементов. Нижеприведенная функция bubble сортирует входной массив методом пузырьковой сортировки.
/* сортировка пузырьковым методом */
float * bubble(float * a, int m, int n)
{
char is=1;
int i;
float c;
while(is)
{ is=0;
for (i=m+1; i<=n; i++)
if ( a[i] < a[i-1] )
{ c=a[i];
a[i]=a[i-1];
a[i-1]=c;
is=1;
}
}
return(a);
}
Пузырьковая сортировка выполняется при количестве действий Q=(n-m)*(n-m) и не требует дополнительной памяти. 2.2.2. Сортировка вставкойУпорядоченный массив B' получается из В следующим образом: сначала он состоит из единственного элемента К1; далее для i=2,...,N выполняется вставка узла Кi в B' так, что B' остается упорядоченным списком длины i. Например, для начального списка B=< 20,-5,10,8,7 > имеем:
B=< 20,-5,10,8,7> B'=< >
B=< -5,10,8,7 > B'=< 20 >
B=< 10,8,7 > B'=< -5,20 >
B=< 8,7 > B'=< -5,10,20 >
B=< 7 > B'=< -5,8,10,20 >
B=< > B'=< -5,7,8,10,20 >
Функция insert реализует сортировку вставкой.
/* сортировка методом вставки */
float *insert(float *s, int m, int n)
{
int i,j,k;
float aux;
for (i=m+1; i<=n; i++)
{ aux=s[i];
for (k=m; k<=i && s[k]
Здесь оба списка В и В' размещаются в массиве s, причем список В занимает часть s c индексами от i до n, а B' - часть s c индексами от m до i-1 (см. рис.26). При сортировке вставкой требуется Q=(n-m)*(n-m) сравнений и не требуется дополнительной памяти.
2.2.3. Сортировка посредством выбораУпорядоченный список В' получается из В многократным применением выборки из В минимального элемента, удалением этого элемента из В и добавлением его в конец списка В', который первоначально должен быть пустым. Например:
B=<20,10,8,-5,7>, B'=< >
B=<20,10,8,7>, B'=<-5>
B=<20,10,8>, B'=<-5,7>
B=<20,10>, B'=<-5,7,8>
B=<20>, B'=<-5,7,8,10>
B=< >, B'=<-5,7,8,10,20> .
Функция select упорядочивает массив s сортировкой посредством выбора.
/* сортировка методом выбора */
double *select( double *s, int m, int n)
{
int i,j;
double c;
for (i=m; i
Здесь, как и в предыдущем примере оба списка В и В' размещаются в разных частях массива s (см. рис.27). При сортировке посредством выбора требуется Q=(n-m)*(n-m) действий и не требуется дополнительной памяти.
Сортировка квадратичной выборкой. Исходный список В из N элементов делится
на М подсписков В1,В2,...,Вm, где М равно квадратному корню из N, и в каждом В1
находится минимальный элемент G1. Наименьший элемент всего списка В
определяется как минимальный элемент Gj в списке Упорядоченные списки А и В длин М и N сливаются в один упорядоченный список
С длины М+N, если каждый элемент из А и В входит в С точно один раз. Так,
слияние списков А=<6,17,23,39,47> и В=<19,25,38,60> из 5 и 4 элементов дает в
качестве результата список С=<6,17,19,23,25,38,39,47,60> из 9 элементов.
Для слияния списков А и В список С сначала полагается пустым, а затем к нему
последовательно приписывается первый узел из А или В, оказавшийся меньшим и
отсутствующий в С.
Составим функцию для слияния двух упорядоченных, расположенных рядом частей
массива s. Параметром этой функции будет исходный массив s с выделенными в нем
двумя расположенными рядом упорядоченными подмассивами: первый с индекса low до
индекса low+l, второй с индекса low+l+1 до индекса up, где переменные low, l,
up указывают месторасположения подмассивов. Функция merge осуществляет слияние
этих подмассивов, образуя на их месте упорядоченный массив с индексами от low до
up (см. рис.28).
Для получения упорядоченного списка B' последовательность значений
В= Приведем пример сортировки списка путем использования слияния, отделяя
последовательности косой чертой, а элементы запятой.
Пример:
Количество действий, требуемое для сортировки слиянием, равно Q=N*log2(N),
так как за один проход выполняется N сравнений, а всего необходимо осуществить
log2(N) проходов. Сортировка слиянием является очень эффективной и часто
применяется для больших N, даже при использовании внешней памяти.
Функция smerge упорядочивает массив s сортировкой слиянием, используя
описанную ранее функцию merge.
Для сортировки массива путем слияния удобно использовать рекурсию. Составим
рекурсивную функцию srecmg для сортировки массива либо его части. При каждом
вызове сортируемый массив делится на две равных части, каждая из которых
сортируется отдельно, а затем происходит их слияние, как это показано на рис.29.
Быстрая сортировка состоит в том, что список В=< K1,K2,...,Kn>
реорганизуется в список B',< K1 >,B", где В' - подсписок В с элементами, не
большими К1, а В" - подсписок В с элементами, большими К1. В списке
B',< K1 >,B" элемент К1 расположен на месте, на котором он должен быть в
результирующем отсортированном списке. Далее к спискам B' и В" снова
применяется упорядочивание быстрой сортировкой. Приведем в качестве примера
сортировку списка, отделяя упорядоченные элементы косой чертой, а элементы Ki
знаками < и >.
Пример:
Время работы по сортировке списка методом быстрой сортировки зависит от
упорядоченности списка. Оно будет минимальным, если на каждом шаге разбиения
получаются подсписки B' и В" приблизительно равной длины, и тогда требуется
около N*log2(N) шагов. Если список близок к упорядоченному, то требуется около
(N*N)/2 шагов.
Рекурсивная функция quick упорядочивает участок массива s быстрой
сортировкой.
Здесь используются два индекса i и j, проходящие части массива навстречу
друг другу (см. рис.30). При этом i всегда фиксирует разделяющий элемент
cnt=s[low], слева от которого находятся числа, не большие cnt, а справа от i
- числа, большие cnt. Возможны три случая: при s[i+1]<=cnt; при s[i+1]>cnt и
s[j]<=cnt; при s[i+1]>cnt и s[j]>cnt. По окончании работы i=j, и cnt=s[i]
устанавливается на своем месте.
Быстрая сортировка требует дополнительной памяти порядка log2(N) для
выполнения рекурсивной функции quick (неявный стек).
Оценка среднего количества действий, необходимых для выполнения быстрой
сортировки списка из N различных чисел, получена как оценка отношения числа
различных возможных последовательностей из N различных чисел, равного N!, и
общего количества действий C(N), необходимых для выполнения быстрой сортировки
всех различных последовательностей. Доказано, что C(N)/N! < 2*N*ln(N).
Распределяющая сортировка. Предположим, что элементы линейного списка В есть
Т-разрядные положительные десятичные числа D(j,n) - j-я справа цифра в
десятичном числе n>=0, т.е. D(j,n)=floor(n/m)%10, где m=10^(j-1). Пусть
В0,В1,...,В9 - вспомогательные списки (карманы), вначале пустые.
Для реализации распределяющей сортировки выполняется процедура, состоящая из
двух процессов, называемых распределение и сборка для j=1,2,...,T.
PАСПРЕДЕЛЕНИЕ заключается в том, что элемент Кi (i=1,N) из В добавляется как
последний в список Bm, где m=D(j,Ki), и таким образом получаем десять списков,
в каждом из которых j-тые разряды чисел одинаковы и равны m.
СБОРКА объединяет списки В0,В1,...,В9 в этом же порядке, образуя один список
В.
Рассмотрим реализацию распределяющей сортировки при Т=2 для списка:
B=<09,07,18,03,52,04,06,08,05,13,42,30,35,26> .
Количество действий, необходимых для сортировки N T-цифровых чисел,
определяется как Q(N*T). Недостатком этого метода является необходимость
использования дополнительной памяти под карманы.
Однако можно исходный список представить как связанный и сортировку
организовать так, чтобы для карманов В0,В1,...,В9 не использовать дополнительной
памяти, элементы списка не перемещать, а с помощью перестановки указателей
присоединять их к тому или иному карману.
В представленной ниже программе функция pocket реализует распределяющую
сортировку связанного линейного списка (указатель q), в котором содержатся
Т-разрядные десятичные положительные числа, без использования дополнительной
памяти; в функции a[i], b[i] указывают соответственно на первый и на последний
элементы кармана Bi.
На рис.31 показана схема включения очередного элемента списка в К-й карман.
Разновидностью распределяющей сортировки является битовая сортировка. В ней
элементы списка интерпретируются как двоичные числа, и D(j,n) обозначает j-ю
справа двоичную цифру числа n. При этой сортировке в процессе РАСПРЕДЕЛЕНИЕ
требуются только два вспомогательных кармана В0 и В1; их можно разместить в
одном массиве, двигая списки В0 и В1 навстречу друг другу и отмечая точку
встречи. Для осуществления СБОРКИ нужно за списком В0 написать инвертированный
список В1.
Так как выделение j-го бита требует только операций сдвига, то битовая
сортировка хорошо подходит для внешней сортировки на магнитных лентах и дисках.
Разновидностью битовой сортировки является бинарная сортировка. Здесь из
всех элементов списка B= |
 Рис.26. Схема движения индексов при сортировке вставкой.
Рис.26. Схема движения индексов при сортировке вставкой.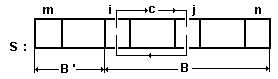 Рис.27. Схема движения индексов при сортировке выбором.
Рис.27. Схема движения индексов при сортировке выбором. Рис.28. Схема движения индексов при слиянии списков.
Рис.28. Схема движения индексов при слиянии списков. Рис.29. Схема сортировки слиянием.
Рис.29. Схема сортировки слиянием.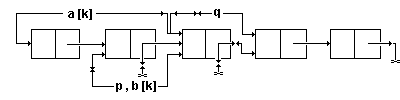 Рис.30. Схема быстрой сортировки.
Рис.30. Схема быстрой сортировки.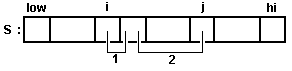 Рис.31. Схема включения очередного элемента списка в карман.
Рис.31. Схема включения очередного элемента списка в карман.
| ||||||||||||||||
| ||||||||||||||||
| Copyright © CompDoc.Ru | ||||||||||||||||
| При цитировании и перепечатке ссылка на www.compdoc.ru обязательна. Карта сайта. |