|
|
||||||||||||||||
| <Добавить в Избранное> <Сделать стартовой> <Реклама на сайте> <Контакты> | ||||||||||||||||
|
||||||||||||||||
| ||||||||||||||||
|
| ||||||||||||||||
Программирование -> Delphi / Pascal -> Алгоритмы нечеткого сравнения строк. | ||||||||||||||||
Алгоритмы нечеткого сравнения строк. Практическое применениеСовсем недавно мне пришлось заниматься конвертацией БД (из парадокса в интербейз) и в контексте этой работы очень плотно пользоваться нечетким сравнением строк. Я написал алгоритм который мне очень помог. Уже после в сокровищнице нашел очерк Кузана Дмитрия (дата публикации 02-12-2002 14:06). Как выяснилось алгоритмы очень похожие, но реализация отличалась и в связи с этим я выявил несколько недостатков собрата моего алгоритма. Привожу краткий анализ, который производился на реальной базе. Допустим необходимо какой либо строке (из одной базы ) подобрать наиболее подходящую строку из другой. Алгоритм примерно такой:
function GetMaxMatch(Source: String; var Name_: String): integer;
var SyncCount, NCount, NCount_: integer;
TempStr: String;
begin
TempStr:= Source;
table1.First;
SyncCount:= 0;
NCount_:= Length(TempStr);
while not(table1.Eof) do
begin
if (CompareStrings(TempStr, table1.FieldByName('NAME').AsString,
MatchCount, NCount) > SyncCount)or
((CompareStrings(TempStr, table1.FieldByName('NAME').AsString,
MatchCount, NCount) = SyncCount)and(NCount < NCount_)) then
begin
SyncCount:= CompareStrings(TempStr,
table1.FieldByName('NAME').AsString, MatchCount, NCount);
NCount_:= NCount;
Result:= table1.FieldByName('Primary Key').AsInteger;
Name_:= table1.FieldByName('NAME').AsString;
end;
table1.Next;
end;
end;
Вернет идентификатор записи(РК) и саму запись(Name_). CompareStrings - как раз нечеткое сравнение (алгоритм ниже). Здесь NCount - кол-во не совпавших символов(в случае если две строки имеют одинаковое число символов совпадения, отсев идет по символам несовпадения). Для теста алгогритма Кузана Д. я применял эту же функцию, а вместо CompareStrings вставлял его функцию. Здесь описан его алгоритм . A это мой:
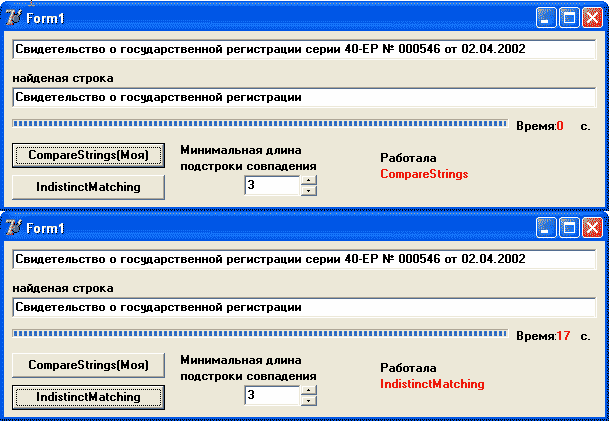
Ниже анализ с учетом времени работы(без выводов - они очевидны)
Пример 1.
Пример 2. Выводы: в некоторых случаях при выборе маленького количества символов совпадения мой алгоритм отрабатывает неправильно (как в примере 2, хотя в примере 3 он тут же исправился), но выигрыш во времени очевиден. Автор: Left Left |

| ||||||||||||||||
| ||||||||||||||||
| Copyright © CompDoc.Ru | ||||||||||||||||
| При цитировании и перепечатке ссылка на www.compdoc.ru обязательна. Карта сайта. |